


Big Data presents challenges and opportunities that need a new set of skills. Current formulations of the Big Data skill set are reductive and restrictive, and programmes set up to hastily address the very real labour market shortage have fallen short of delivering on the promise. Below, Mihnea Moldoveanu demonstrates that a comprehensive re-conceptualisation of the Big Data skill set is required to redress the wave of disappointed expectations at the ways in which selection and skill development programmes have approached this new – and very much alive – opportunity and challenge.
Big Data – we are told – represents the business opportunity and challenge of the decade. The opportunity is that of using the 2.5 quintillion bytes of data generated every day – 90 percent of which has been generated during the last eight quarters – in order to make more informed and responsive business decisions on the basis of solving the problems the world throws up more accurately, reliably and efficiently. The challenge – we are also told – is to tame the volume and variety of the data with the right velocity to produce timely inferences and insights.
[ms-protect-content id=”9932″] Accepted wisdom is that we are falling short of the Big Data challenge on account of the dearth of “deep analytical skills” – McKinsey & Co estimates that the labour market is between 140,000 and 190,000 new data scientists short of responding to the Big Data challenge. Academia – always quick to exploit a perceived imbalance in the demand and supply of talent to the end of appropriating a new stream of cash flows – has responded with a flurry of new Masters’ programmes in “Big Data analytics” – some 40 new programmes during the last 4 years in North America alone – which purport to equip graduates with Big Data skills by re-deploying courses in econometrics, statistics and operations research developed for the “small data” era in handsomely tailored – and premium-priced – diploma-bearing packages. Massively Open Online Course offerings of promising “Big Data” skills have grown fifty-fold during the last two years, and very muscular “catch-all” Big Data analysis firms like Palantir, Sentient and Cloudera have emerged as providers of “insight-on-demand”.
Accepted wisdom is that we are falling short of the Big Data challenge on account of the dearth of “deep analytical skills” – McKinsey & Co estimates that the labour market is between 140,000 and 190,000 new data scientists short of responding to the Big Data challenge. Academia – always quick to exploit a perceived imbalance in the demand and supply of talent to the end of appropriating a new stream of cash flows – has responded with a flurry of new Masters’ programmes in “Big Data analytics” – some 40 new programmes during the last 4 years in North America alone – which purport to equip graduates with Big Data skills by re-deploying courses in econometrics, statistics and operations research developed for the “small data” era in handsomely tailored – and premium-priced – diploma-bearing packages. Massively Open Online Course offerings of promising “Big Data” skills have grown fifty-fold during the last two years, and very muscular “catch-all” Big Data analysis firms like Palantir, Sentient and Cloudera have emerged as providers of “insight-on-demand”.
Forward looking analysists have warned that the Big Data hype cycle is entering the trough of disillusionment that follows the wave of exuberantly inflated expectation , but that may be as much on account of the hurriedly improvisational nature of the reaction from labour market and talent suppliers to the Big Data “opportunity” as because of always-lurking “bubble” dynamics. We have over-simplified the Big Data challenge as being one of storing data and getting computers to do things with it, and that has led to a mis-specification of the Big Data Challenge to the labour market, on which we have hurried to act. Internalising the real challenge of Big Data will involve a careful mapping of the skill sets that the “sense-to-bits” revolution in the way we interact with the world entails, and the reconstruction of training and selection engines that deliver.
Only once we have broken out of the straitjacket of thinking about the Big Data Challenge as a bigger version of the causal and predictive analytics problems we solved on smaller data sets, under less time pressures and with fewer programming languages at our disposal, will we be in a position to face the Big Data Challenge in a way that addresses the Big Data opportunity set. And that opportunity set is significantly broader than what we currently imagine, ranging from continuous learning guided by sensors that tell us when and how we are most likely to learn, to personalised health care that creates adaptive maps of gene-environment-behaviour interactions to produce real time personalised advice and intervention – just to name two $4 Trillion-range global industries that have not even started to feel the seismic rattles of the senses-to-bits-to-solutions earthquake.
A Little Map of Big Data Skills: Breaking out of the Straitjacket
Current reductivisms about Big Data skills have a common root, to which language bears witness. Data is the plural of datum which is translated from Latin as “given”. But givenness – a red herring even in the natural sciences – is even less obvious when it comes to measurements produced by human behaviour. Purchasing behaviour, mating behaviour, and web surfing behaviour are radically different from the behaviour of electrons in a circuit or a plasma, because they are produced by decision and choice processes that are susceptible to insight, feedback and re-interpretation.
Modelling
Big Data challenges are rarely just about storage. As Adam Jacobs has pointed out, we can store 16 byte-field-long data on each one of the 7 billion humans currently around on a single Dell enterprise server; but, our ability to run sophisticated tests of hypotheses linking these characteristics to derive useable insights is severely limited by the hardware we can synchronously access, and the complexity of the algorithms we use to code the models we build. Ingenuity – the ability to search for the most efficient ways of searching for insight – is the rate-limiting skill at the level of the humans who shall write the code, just as Moore’s Law-type regularities constrain our abilities to perform calculations and calls to memory. Moore’s Law will not by itself take us to the computational prowess required to process the volume of data required to give personalised medical advice on the basis of remote sensing of milieu and databases of gene-environment interactions, even if we do not take thermodynamic limits into consideration: we need to consistently develop the algorithms that increase the number of bits of new information per executable operation.
Sensing
The fact that data is decidedly not given entails we must pay close attention to the interactive ways in which we create it. “The mind and the world together make up the mind and the world” – the philosopher Hilary Putnam notably quipped – and science has made as much progress by disciplined postulation of model and hypothesis as by the judicious transformation of quality into quantity. Sensing – the uniquely human skill by which raw feelings and perceptions are turned into interpretable and communicable objects and events, and onward into measurable quantities we can turn into fields of bits and bytes. “Quantifying” anger, disgust, malaise and angst are Big Data skills that lie outside of the domain of the cognitive skills we have become so routinised at (trying to) transfer. Yet such quantifications are critical to quintessential Big Data projects like the remote sensing and optimisation of the emotional landscapes of learning, collaborating, managing.
Accordingly, the Big Data “virtuoso” will be a consummate phenomenologist – someone capable of sensing, describing and interpreting raw feelings so that they may be turned into the words and measurements that create the “given” evidence. And, of course, where there is quantity, there are critical efficiency gains to be realised by delegating mechanical tasks to the zero-marginal-cost-of-computation machine – the computer and the wearable device – which means that this is no “usual” phenomenologist, but one who can also design and write the code and build the interfaces that will turn sense into bits and bits into databases.
Informing
We often refer to the “variety” of data comprising a Big Data set, but a single word does not do justice to the varieties of variety of Big Data. We have varieties of format and formal languages; varieties of operating systems and computational and storage platforms; varieties of substantive format of the data (text, numbers and other symbols); and varieties of the access protocols required to enter different databases. Database design experts have quickly realised that getting data into a database is far easier than getting it out – and the Big Data skill set accordingly must comprise the ability to design, merge, fuse and search data- and knowledge-bases, once again by deploying algorithms that do so efficiently on the hardware the databases currently inhabit.
It is fascinating, moreover, to see how the security-privacy behemoth of a problem in the corporate world has been hived off artificially from the Big Data problem – as if either encryption and privacy/authentication solutions designed for small data are seamlessly scalable, or Big Data somehow does not live in the same gruesome, politically charged, hacker-and-paparazzi infested social sphere in which all data lives. Neither is true, of course: building a real collaborative platform for investigating patterns of neurological dysfunction across a very large population cared for by multiple health care organisations is a Big Data problem “from Hell” precisely because of the special security, authentication and privacy problems that must be addressed, concurrently, on multiple non-compatible archival and storage systems – and, very quickly.
Communicating
Big Data creates Big Problems – as I have argued in a company article, and Big Problems yield more readily to insight that is collaboratively produced than to the efforts of any one expert – or expert – appended to a machine. Collaboration – and not just coordination or co-mobilisation – is the key to the creation of collective intelligence (and, ingenuity) – which transcends the sum of the problem solving prowess of the individuals making up the problem solving team. The key to collaboration is effective, precise and connected communication – which encompasses both the presentational skills of synthesising, structuring, and arguing and the relational skills of dialogically deliberating and taking perspectives foreign to one’s own.
“Relating” is a far more sophisticated skill than we would be led to believe by its “soft”-sounding name. Many enterprises confronting Big Data challenges are flummoxed by the challenge of cultivating a managerial team that can effectively communicate with the technically trained suite of coders, developers and solutions providers – which involves a convex combination of understanding the technical language systems and architectural and functional challenges of new database design and integration and the traditionally “liberal arts-ish” skills of articulating one’s thoughts with precision and sensitivity and reading the emotional landscapes of individuals and groups off the often opaque set of body signals, gazes and tone, pitch, rhythm and syncopation of voiced speech. And, of course, coding will not leave us alone here either, as the technologies for collaborating – emails and wiki-machines – must be reinvented to facilitate the trustful sharing, pooling, dissemination, tunnelling and aggregation of relevant information in the right time, at the right place, and the minds of the right people.
The Map at a Glance – and a Fragment of an Insight
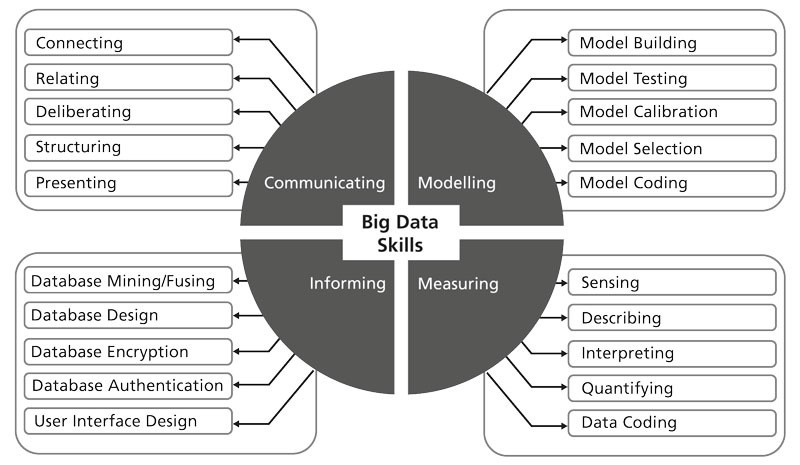
The map of Figure 1 is vastly larger in both scale and scope than what has been taken to be the canon of “Big Data skills”. Additionally, it highlights skills that most of the programmes purporting to address the Big Data talent shortage – created and promoted by silo-based, disciplinary units of academic institutions taking a supply-centric view of education – are not currently either selecting for or seeking to transfer. The skills map, accordingly, also functions as a “map of the gap” – of a gap that has been created by talent-recruitment and training organisations that have focused on what they can and like to do – rather than what is needed, or optimal. Creating the recruitment and training vehicles that deliver on the Big Data skill set requirement will represent a test of the very skills of collaboration and communication that are part of this ideal arsenal – and it may be a set of skills that quintessential problem solving organisations that have been at the forefront of articulating the Big Data challenge – like McKinsey, BCG, Deloitte, Google, Apple, Facebook and IBM – may be better equipped to address than academic institutions currently are. But the Big Data challenge – and the opportunities the senses-to-insight era is heralding – has, I predict, a curious characteristic: it will not go away. Unlike Texas oil, telecom equipment and chips, mortgage backed securities, and any of a number of fads and bubbles you can remember – this one has depth and resilience precisely because of the ever changing landscape of the techniques, technologies and tools by which reality is sensed, measured, stored, and made sense of through the full set of capabilities of human and machine combined.
About the Author
 Mihnea Moldoveanu is Professor of Business Eco-nomics, Desautels Professor of Integrative Thinking, Associate Dean of the MBA Programme and the Director of the Desautels Centre for Integrative Thinking at the Rotman School of Management and the Mind Brain Behavior Hive at the University of Toronto. Prof. Moldoveanu’s work has been published in leading journals and is the author of six books, most recently Epinets: The Epistemic Structure and Dynamics of Social Networks (with Joel Baum) (Stanford University Press, 2014), and his forthcoming The Design of Insight: How to Solve Any Business Problem (with Olivier Leclerc) (Stanford University Press, 2015). Prof. Moldoveanu is also the founder of Redline Communications, Inc., and was recognised as one of Canada’s Top 40 Under 40 in 2008 for his contributions to the academic and business worlds.
Mihnea Moldoveanu is Professor of Business Eco-nomics, Desautels Professor of Integrative Thinking, Associate Dean of the MBA Programme and the Director of the Desautels Centre for Integrative Thinking at the Rotman School of Management and the Mind Brain Behavior Hive at the University of Toronto. Prof. Moldoveanu’s work has been published in leading journals and is the author of six books, most recently Epinets: The Epistemic Structure and Dynamics of Social Networks (with Joel Baum) (Stanford University Press, 2014), and his forthcoming The Design of Insight: How to Solve Any Business Problem (with Olivier Leclerc) (Stanford University Press, 2015). Prof. Moldoveanu is also the founder of Redline Communications, Inc., and was recognised as one of Canada’s Top 40 Under 40 in 2008 for his contributions to the academic and business worlds.
[/ms-protect-content]

 Can Encourage Collaboration Between Departments Beyond Formal Structure")




























 Can Encourage Collaboration Between Departments Beyond Formal Structure")


